Dr Boris Guennewig, Senior Lecturer, The University of Sydney.
Boris is a senior Lecturer and head of the FOREFRONT BIOINFORMATICS and STATISTICS RESEARCH GROUP.
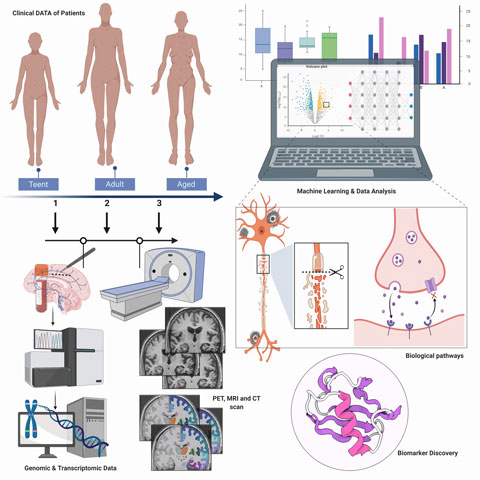
He is a research scientist/bioinformatician/statistician specializing in the development of infrastructure, software and pipelines to manage, analyze and mine large complex datasets in medical research. Using structured, semi-structured and unstructured data, his research focuses on the identification and characterization of genetic variation and transcriptional changes influencing complex human diseases (such as frontotemporal lobe dementia, bipolar disorder, Parkinson’s and Alzheimer’s disease, etc.). He achieves this through the functional integration of high-dimensional biological (omics) data, in combination with his statistical, genetics and data mining skills. Boris believes that assimilating and modelling multi-modal data (i.e. imaging, clinical and omic data) is key to uncovering the genotype-phenotype interaction and how this relationship affects complex traits.